Innovations Behind Falcon-40B: A Leader in Open Source LLMs
Written on

In an intriguing development, Falcon has taken the lead on HuggingFace's open LLM leaderboard. This advanced language model is offered in several configurations, including 7B, 7B-Instruct, 40B, and 40B-Instruct. Notably, it is now available for commercial use. Interested users can examine the license here, marking a significant milestone for both open-source advocates and companies looking to utilize LLMs for their product innovations.
Interestingly, Falcon has outperformed the LLaMA 65B model, even though the latter boasts a higher parameter count.
This article explores the factors contributing to Falcon's exceptional performance. What distinguishes this model? What innovative strategies have propelled it to such impressive achievements?
We will closely examine RedefinedWeb, the dataset that served as the training foundation for Falcon. Although the specifics of the model paper have not yet been published, we know that it employs FlashAttention and MultiQuery Attention. I will provide a detailed analysis of the paper once it becomes available, so stay tuned for updates.
LLMs Scaling Laws & Paper Introduction
Understanding the scaling laws governing Large Language Models (LLMs) is vital for discussing performance improvements. To enhance a model's effectiveness, it is essential to "scale up" the model. This involves increasing the model size by expanding the number of parameters, while simultaneously increasing the volume of training data.
However, this model of advancement presents challenges, primarily because data, despite being abundant, is not infinite. These issues are exacerbated by considerations such as data quality, copyright, and licensing concerns. Unfortunately, a significant portion of available data fails to meet high-quality standards.
For instance, a vast amount of user-generated content on the internet contributes to the data pool but is often plagued by grammatical mistakes and factual inaccuracies. Conversely, high-quality data can be found in well-curated books, select web resources, and insightful social media discussions. Yet, acquiring this premium data can be challenging due to proprietary issues and the need for human oversight to evaluate its quality.
Thus, scaling models poses a dual challenge — increasing size while maintaining the integrity and legality of the input data.
Falcon Team Contributions
To address these challenges, the Falcon team has made several notable contributions:
- They pioneered the development of RedefinedWeb, an English pretraining dataset sourced exclusively from the web. This dataset, encompassing an impressive five trillion tokens, exemplifies high-quality data collection.
- The Falcon team demonstrated that utilizing web data alone can yield models that outperform those trained on both public and private curated datasets. This breakthrough, supported by zero-shot benchmarks, challenges conventional wisdom regarding data quality.
- The team released a substantial extract of RefinedWeb, consisting of 600 billion tokens, to the public. Additionally, they made available Large Language Models trained on this dataset, featuring a parameter count of 1/7 billion. These releases aim to establish a new benchmark for high-quality web datasets in the natural language processing community.
How Falcon Team Created RedefinedWeb Dataset?
The Technology Innovation Institute (TII) initially focused on creating a robust dataset specifically designed for the English language. This linguistic focus facilitates enhanced quality control. Moreover, they established a set of design principles to guide the dataset creation process, ensuring a meticulous and consistent methodology throughout.
Design Principles
- Scale First: Concentrate on developing a dataset of 3–6 billion tokens aimed at training models with 40–200B parameters, avoiding human intervention in the dataset curation process. This leads to focusing on Common Crawl instead of utilizing separate datasets.
- Strict Deduplication: Implement a rigorous filtering pipeline utilizing both exact and fuzzy deduplication techniques.
- Neutral Filtering: Filter the remaining data using straightforward heuristics like URL filtering. They refrain from employing any ML-based methods to avoid introducing bias into the data.
The cumulative effect of these guiding principles resulted in the creation of a streamlined pipeline. This process not only meticulously refines the datasets but also preserves a substantial quantity of tokens necessary for training a Large Language Model.
The essence of this pipeline is succinctly illustrated in the figure below:
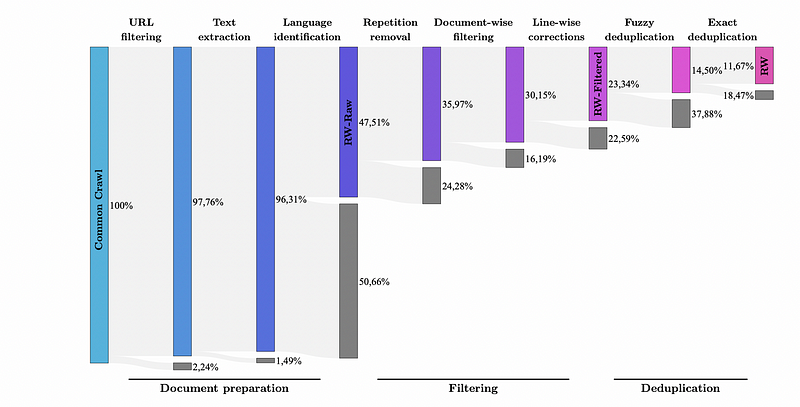
If the image above is unclear, don't worry; I had trouble grasping it at first too. Let's explore the steps together.
Macrodata Refinement Steps
- Reading Data: Read the dataset in WRAC (raw HTML) format using the warcio library, avoiding the WET format due to unwanted buttons, ads, and irrelevant text.
- URL Filtering: Remove 4.6 million URLs using a blocklist of domains. They also compute a score based on the words in the URL from a list weighted by the severity of the words.
- Text Extraction: Extract the main content of the page, disregarding menus, footers, and headers, using trafilatura for extraction and applying regular expressions to ensure formatting and URL removal.
- Language Identification: Utilize fastText to detect the language at the document level, rejecting documents with scores below 0.65 and focusing on English.
- Repetition Removal: Identify document-level repetitions using the same heuristics outlined in this paper. They eliminate any document with excessive line, paragraph, or n-gram repetition.
- Document-Wise Filtering: Apply filtering heuristics to documents affected by machine-generated spam. Removing outliers based on overall length, symbol-to-word ratio, and other criteria ensures the document represents natural language.
- Line-Wise Correction: Even after numerous corrections, some discrepancies may remain at the line level, such as social media counters and similar content. They implement a line filter targeting these unwanted elements; if 5% of a document is removed, the entire document is discarded.
- Fuzzy Deduplication: Remove similar documents by applying MinHash, which eliminates templated documents and repetitive SEO text.
- Exact Deduplication: Remove sentence-level duplicates by eliminating matches of 50 consecutive tokens or more.
- URL Deduplication: Divide CommonCrawl into 100 segments and search for duplicated URLs. Keep URLs from each segment while removing them from subsequent segments.
The final product, representing only 11.76% of the CommonCrawl data, culminates in what is now acknowledged as the gold standard 5 trillion token RefinedWeb dataset.
Evaluation
To assess their dataset, they measure Zero-Shot generalization across various tasks using Eleuther-AI Harness benchmarks. They compare their results against curated datasets such as C4, The Pile, and OSCARs. All models were trained with identical architectures and pretraining hyperparameters.

As illustrated by our analysis, models trained on refined web data significantly outperform those trained on other curated datasets, highlighting the efficacy of Falcon's methodology.
To corroborate these findings, they trained full-scale models ranging from 1–7 billion parameters on 350 billion tokens and also evaluated EleutherAI LM.
The evaluation process was divided into four distinct segments, each encompassing various tasks, enabling a thorough comparison against an array of models. This division is comprehensively depicted in the table below:
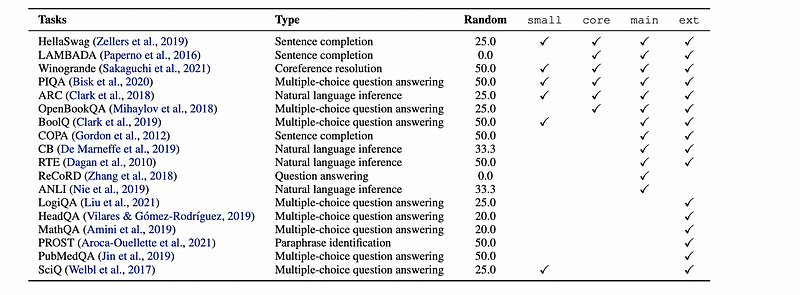
- ‘Small’ is designated for ablation tests and experimental purposes.
- ‘Core’ is tailored for common tasks associated with publicly available models.
- ‘Main’ is based on tasks derived from GPT-3 and PaLM.
- ‘Ext’ is predicated on tasks stemming from the Scaling Group and the BigScience Architecture.
The results based on ‘core’ and ‘ext’ are illustrated in the figure below:
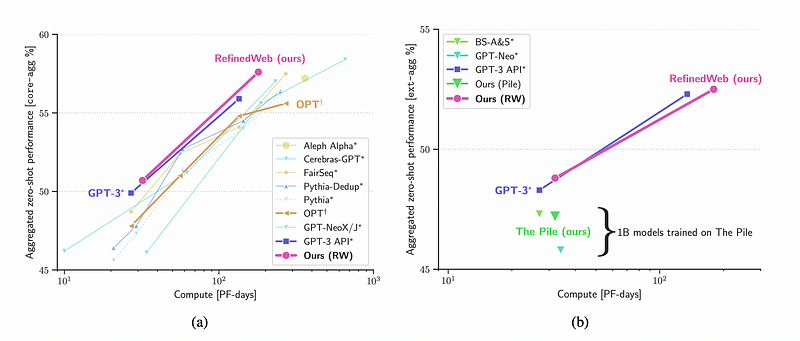
On average, models trained on RefinedWeb clearly outperform their counterparts on both ‘core’ and ‘ext’ tasks, further emphasizing the advantages of this innovative training methodology.
Conclusion and Takeaways
- As we continue to scale, we increasingly depend on internet data and crawls. However, this dependence is contingent upon implementing multiple refining filters, thorough deduplication, and various quality-enhancement techniques.
- Models trained solely on web data can surpass curated datasets when subjected to proper cleaning processes.
- A new public extract of 600 billion tokens from Redefined Web has been released, presenting unprecedented opportunities for research and development in the field.
- Although RefinedWeb concentrates on English, Falcon 40B is trained on multilingual data, allowing for its application on HuggingFace.
I trust this article has shed light on the creation of the Falcon dataset.
Feel free to clap, follow, and comment if you enjoyed this article!
Stay connected by reaching out via LinkedIn with Aziz Belaweid or on GitHub.
Stay informed with the latest news and updates in the creative AI realm — follow the Generative AI publication.