Meta-Transformer: A Singular Solution for Multimodal Processing
Written on

The human brain is adept at processing various sensory inputs concurrently. However, achieving this in deep learning models is challenging. Understanding the significance of this capability and exploring avenues for success is crucial.
Expanding Transformers Across Modalities
Transformers have revolutionized the field, initially designed for language processing but later adapted for diverse modalities. Following the introduction of the original transformer, vision transformers emerged, allowing the application of this framework to images. Over time, transformers have also been utilized in video, music, and graph analysis.
The Challenge of Multiple Modalities
Instead of utilizing separate transformers for every single modality, researchers realized that a unified model could enhance understanding across modalities. This approach facilitates the simultaneous learning of text and images, establishing a foundation for further integration.
The Case for a Unified Model
However, each modality presents unique characteristics, making it difficult for a model trained on one to adapt to another. For instance, images exhibit redundancy due to pixel density, whereas text does not share this trait. Audio files display temporal variations, and videos combine spatial and temporal patterns, while graphs illustrate complex relationships.
To address these differences, distinct neural networks were often employed for each modality. Some models exist that can handle both images and text together, yet extending this capability to additional modalities remains a challenge.
Can One Model Handle Multiple Modalities?
Recent research indicates that a single model can effectively manage up to twelve modalities, including images, natural language, point clouds, audio spectrograms, video, infrared, hyperspectral, X-ray, IMU, tabular, graph, and time-series data.
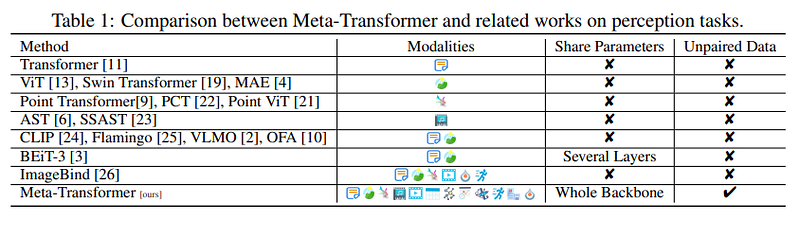
Introducing the Meta-Transformer
The Meta-Transformer proposes a singular model for all modalities, comprising three main components: a modality specialist for token conversion, a shared encoder for extracting common representations, and task-specific heads for downstream applications.
> Specifically, the Meta-Transformer first converts multimodal data into token sequences that share a common manifold space. A frozen-parameter shared encoder then extracts representations, which are fine-tuned for specific tasks using lightweight tokenizers and task heads. This streamlined structure enables effective learning of both task-specific and modality-generic representations.

Tokenization from Data to Sequence
The initial step involves converting data from various modalities into token embeddings of uniform size, thus transforming them into vectors suitable for processing by the model.
Each modality undergoes a specific tokenization phase: a text tokenizer for text, flattening for images, and so forth.
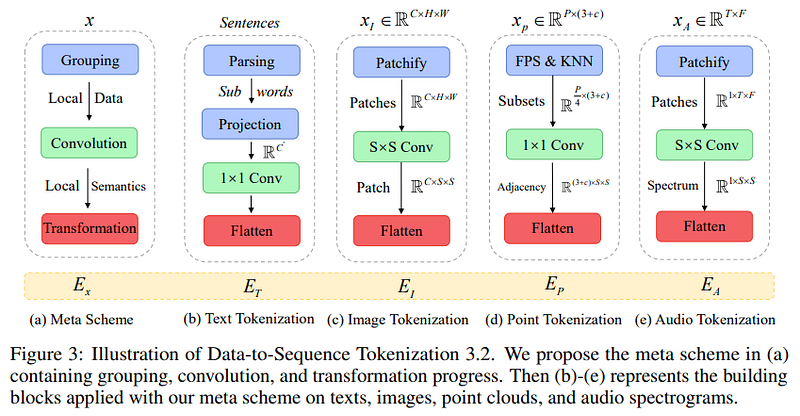
Unified Encoder
Subsequently, the tokens are embedded and processed through a single transformer encoder with frozen parameters, generating a representation from the diverse token embeddings.
The authors employed a vision transformer (ViT) pre-trained on the LAION-2B dataset, a vast collection of images, utilizing contrastive learning techniques. Each token sequence is appended with a special token and positional encoding to indicate token order.
Task-Specific Heads
After obtaining the embeddings and representations, task-specific heads, typically made up of multi-layer perceptrons, are introduced to the model.
A Multimodal Approach for a Multimodal World
The authors conducted experiments across various domains, including:
- Text understanding
- Image understanding
- Infrared, X-ray, and hyperspectral data analysis
- Point cloud recognition
- Audio and video recognition
- Time-series forecasting
- Graph analysis
- Tabular data processing
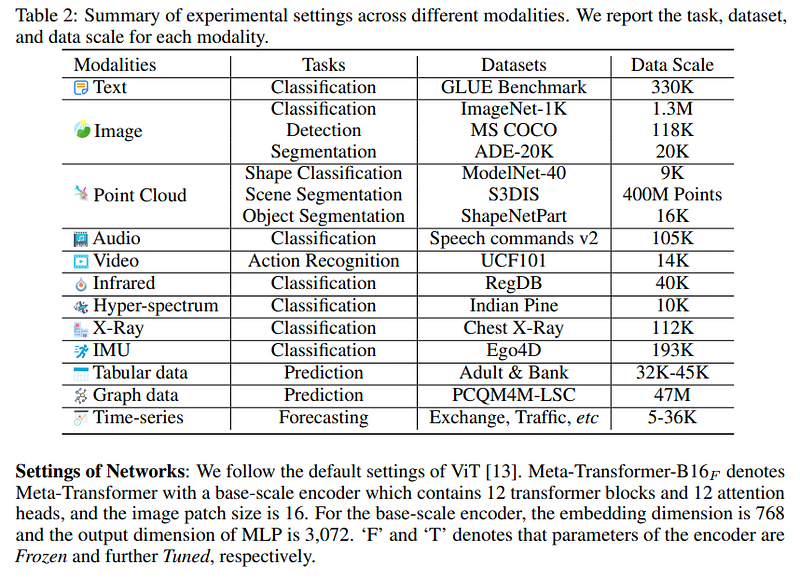
As illustrated in the results, while the model performs admirably on various NLP tasks, it does not surpass models trained specifically for those tasks. The same trend is observed in image understanding tasks, where specialized models excel.
Interestingly, the authors highlight the model's applicability to infrared, hyperspectral, and X-ray data. This versatility suggests that one model can effectively manage multiple data types simultaneously, such as various medical imaging results.
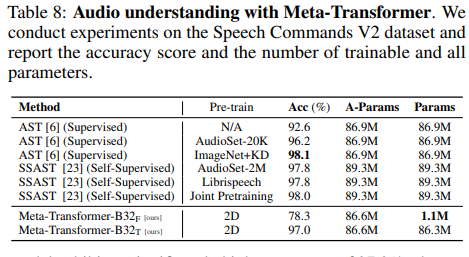
The Meta-Transformer also excels in processing video data, highlighting its multi-modal capabilities while maintaining a reduced parameter count.
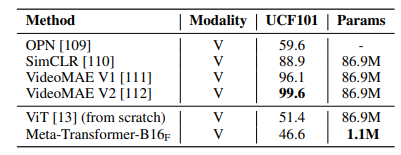
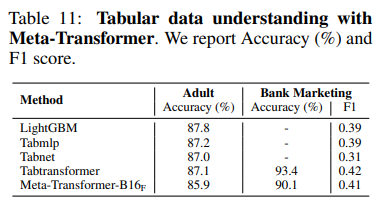
Additionally, the model shows promising results in time series and tabular learning, demonstrating its proficiency across various data forms.
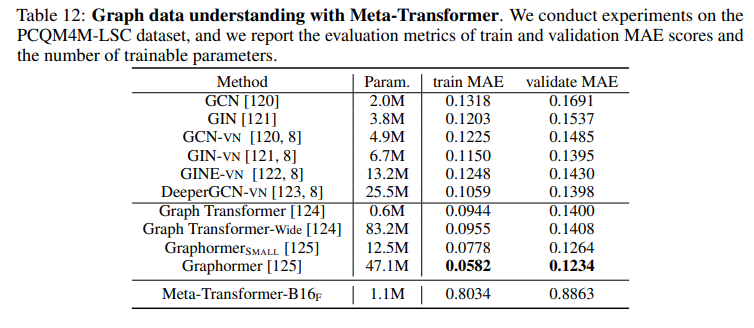
It also yields effective results in graph data analysis.
Each modality has its nuances, typically necessitating distinct models. The authors have made their code available for those interested in exploring this further.
GitHub - invictus717/MetaTransformer: Meta-Transformer for Unified Multimodal Learning
Meta-Transformer facilitates unified multimodal learning. Contribute to the development of invictus717/MetaTransformer at: github.com
Conclusions and Insights
Each modality presents unique challenges, and creating a model with the appropriate inductive bias for one modality may not translate effectively to another. Thus, developing a single framework that accommodates all modalities simultaneously is complex.
The preprocessing phase allows the model to handle multiple modalities efficiently. While the encoder is trained once, the model's simplicity is an advantage. The research demonstrates the model's competitive edge across various data types, although it still lags in tabular and graph learning. Notably, the Meta-Transformer lacks temporal and structural awareness critical for video understanding and similar applications.
Moreover, this study reinforces the adaptability of transformers to a wide range of modalities. The authors, however, point out the model's quadratic complexity, which may hinder scalability with token size. Finding an alternative that avoids this quadratic cost while maintaining performance remains a challenge.
Welcome Back 80s: Transformers Could Be Blown Away by Convolution
The Hyena model illustrates how convolution may outperform self-attention in certain scenarios.
Ultimately, this research is noteworthy as it adeptly integrates up to twelve modalities, marking a significant step toward establishing a modality-agnostic framework.
If you found this article engaging:
You may explore my other writings, subscribe for updates, become a Medium member for full access to stories (affiliate links for which I earn a small commission), or connect with me on LinkedIn.
Additionally, here’s the link to my GitHub repository, where I plan to consolidate code and resources related to machine learning and artificial intelligence.
GitHub - SalvatoreRa/tutorial: Tutorials on machine learning, artificial intelligence, data science…
For further reading, consider my recent articles:
- All You Need to Know about In-Context Learning: What it is and how it empowers large language models.
- Is ChatGPT losing its capabilities?: Examining the latest performance of GPT-4.
- META LLaMA 2.0: The Most Disruptive AInimal: How Meta LLaMA is reshaping chatbot and LLM usage.
- CodeGen2: A New Open-Source Model for Coding: Exploring SaleForce’s impact on efficient coding model design.