Leveraging Deep Learning to Diagnose Eye Conditions: Insights from Google
Written on
Through advancements in deep learning, Google has recently unveiled a research paper demonstrating that an AI model can predict various systemic biomarkers using just a photograph of the eye.
How is this achieved? What methodologies led to these findings? Why do they matter? This article delves into these questions.
The Eye as a Diagnostic Tool
Typically, diagnosing medical conditions necessitates the use of costly equipment and skilled professionals to interpret the results. However, not all healthcare facilities have access to such technology, and there may be a lack of specialists available.
For instance, diagnosing diabetic retinopathy (DR) involves using a fundus camera to examine the back of the eye, which must then be evaluated by a trained expert. This process can also reveal other health issues, including cardiovascular risk, anemia, chronic kidney disease, and other systemic indicators.
Prior to this research, it was believed that fundus images could be analyzed through machine learning algorithms. In 2017, a groundbreaking study from Google demonstrated that external photographs of the eye could facilitate the detection of diabetic retinal diseases and poor blood sugar regulation.
The authors analyzed images of 145,832 diabetic patients from California and other groups, utilizing Inception V3, which had been pre-trained on ImageNet. They found:
> Our results indicate that external eye images reveal signals of diabetes-related retinal issues, suboptimal blood sugar levels, and elevated lipid levels. (source)
Inception V3 achieved state-of-the-art accuracy of over 78.1% on ImageNet, demonstrating greater computational efficiency than earlier models. This success was attributed to its parallel structures and robust regularization techniques. The authors also established key principles that influenced the convolutional neural network (CNN) landscape for subsequent years:
- Avoiding representational bottlenecks, ensuring gradual size reduction from inputs to outputs.
- Facilitating faster training through higher-dimensional representations processed locally within the network.
- Employing spatial aggregation to minimize dimensionality loss.
- Maintaining a balance between network width and depth.
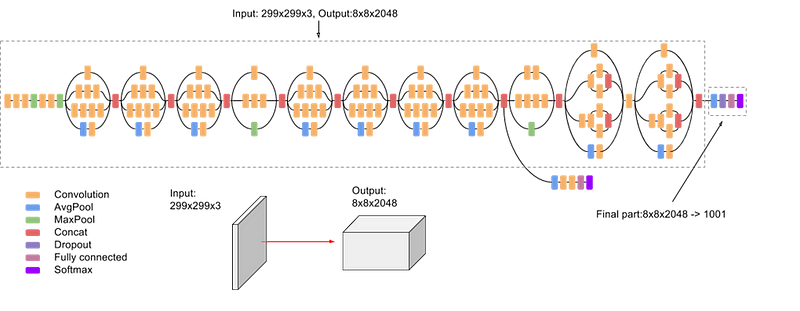
Using traditional supervised learning, the authors trained the model with images of patients' eyes as ground truth for diseases like diabetic retinal disease and elevated glucose or lipid levels. The model exhibited an area under the curve (AUC) exceeding 80% for diabetic retinal disease diagnosis, with slightly lower results for glucose and lipid levels.
These findings are significant, as systemic markers are typically derived from the front eye. This study established that deep learning could extract similar information from external images.
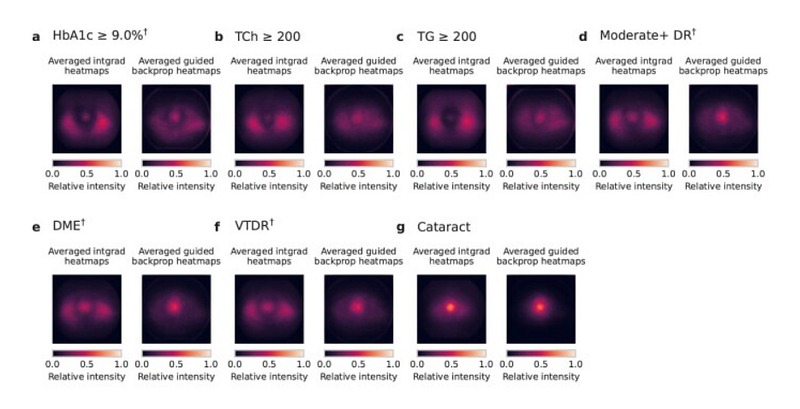
Moreover, through ablation studies and saliency maps, the researchers gained insights into the model's prediction mechanisms:
> The ablation analysis revealed that the image center (pupil/lens, iris/cornea, and conjunctiva/sclera) is considerably more crucial than the periphery (e.g., eyelids) for all predictions. The saliency analysis confirmed that the deep learning system is significantly influenced by the central areas of the image. (source)
This research indicates that for the increasing diabetic population, certain parameters can be evaluated without specialized medical personnel. Additionally, external eye images could be captured using basic cameras.
> Future studies should address whether further requirements for lighting, photo distance, angle, lens quality, or sensor fidelity exist, with hopes that disease detection through external eye images can become widely accessible across various settings, from clinics to home environments. (source)
Currently, these models are not designed to replace comprehensive screenings but rather to identify patients who may benefit from additional evaluations, proving more effective than traditional questionnaires.
The authors continued their assessment of the model, acknowledging potential biases and inclusivity issues. One major challenge in AI applications within biomedical fields is the risk of misleading results stemming from unrepresentative datasets.
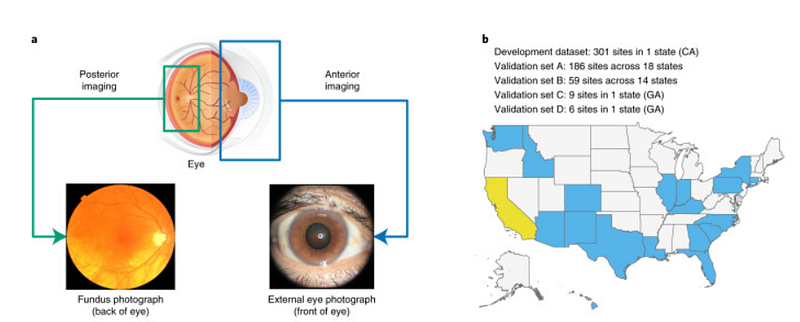
> Our development dataset included a diverse range of locations in the U.S., comprising over 300,000 de-identified photos from 301 diabetic retinopathy screening sites. Our evaluation datasets included over 95,000 images from 198 sites across 18 U.S. states, incorporating datasets predominantly featuring Hispanic or Latino patients, majority Black patients, and non-diabetic patients. Extensive subgroup analyses were performed considering various demographic and physical characteristics (e.g., age, sex, race, cataract presence, pupil size, and camera type), controlling for these variables as covariates. (source)
The Eye as a Reflection of Health
The researchers at Google and their collaborators found this approach promising, leading them to explore its application for other health markers and diseases.
Thus far, the team has demonstrated that their model can effectively diagnose eye-related conditions like diabetic retinopathy. However, the complexity of diagnosing numerous diseases (due to necessary tests, expensive equipment, and accessibility issues) raises the question of whether the model can also detect indicators of other health conditions through eye images.
Could this approach apply to other diseases?
Deep learning models have the ability to recognize subtle patterns that might elude non-experts. With this in mind, Google researchers sought to determine if they could identify cardiovascular risk factors through ocular fundus images.
Cardiovascular diseases are the leading global cause of death, and early detection could save countless lives. Risk stratification plays a crucial role in managing at-risk populations. Typically, various variables (medical history, lab results, etc.) are needed for diagnosis and stratification, but data might sometimes be incomplete.
In their findings, the authors demonstrated that it is feasible to predict certain patient characteristics (helpful in cases of incomplete data) such as BMI, age, gender, and smoking status, in addition to cardiovascular disease-related parameters like systolic and diastolic blood pressure.
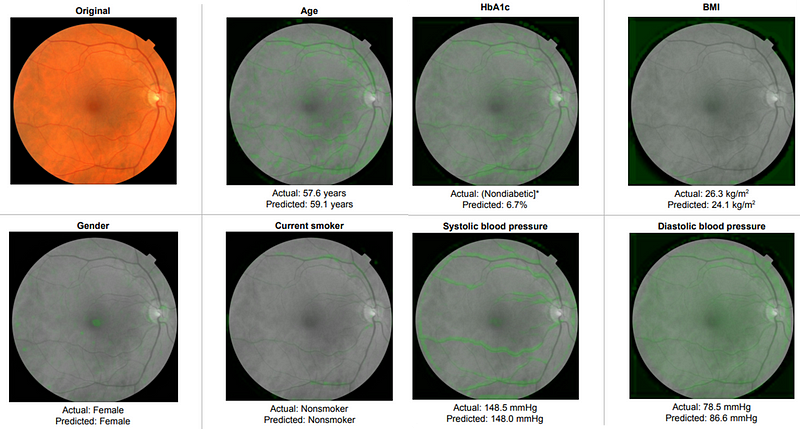
The same Inception V3 model was utilized for this study. To manage continuous variables, they employed binning—segmenting variables into different ranges (e.g., <120, 120–140, 140–160, and ?160 for SBP).
The authors also applied a technique called soft attention to identify regions associated with specific features. In essence, soft attention considers various subregions of images, relying on gradient descent and back-propagation without requiring a dedicated attention mechanism.

In a subsequent study, the authors explored anemia, a condition affecting over 1.6 billion people that necessitates blood tests to monitor hemoglobin concentration—a process that can be invasive and carries risks.
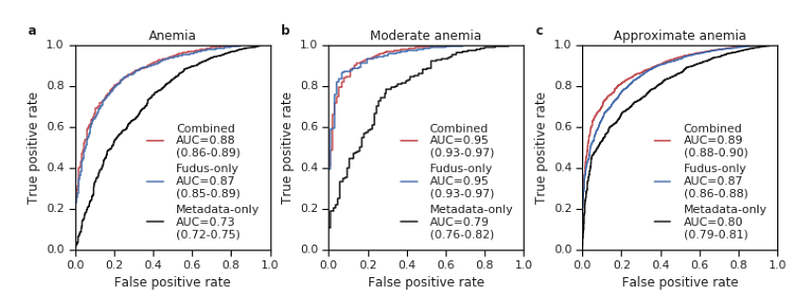
For this research, they utilized Inception V4, an enhanced version of the previous model, integrating residual connections to optimize performance. Inception V4 demonstrated that various Inception block types (comprising both parallel and sequential convolution layers) could be effectively utilized.
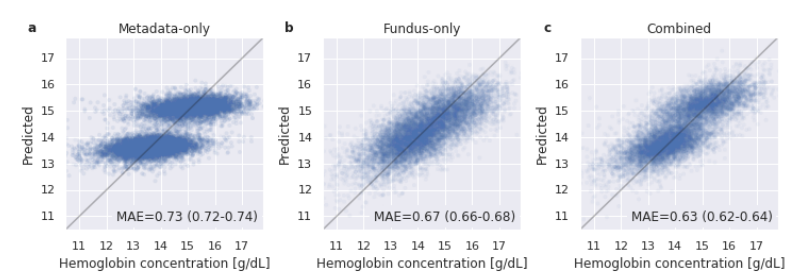
The findings suggested that the approach extends beyond mere classification (determining if a patient has anemia) to predicting hemoglobin concentration (a regression task). The authors trained separate models for both classification and regression tasks (Inception V4 pre-trained on ImageNet).
For regression, they used mean squared error as the loss function (instead of cross-entropy) and generated final predictions by averaging the outputs from ten models trained similarly.
A Broader Perspective
To date, researchers have primarily focused on a limited number of parameters. However, blood tests can typically assess many more indicators in a single examination. Could an eye photo model estimate a range of systemic biomarkers?
Google recently explored this concept and published their findings:
> A deep learning model for novel systemic biomarkers in photographs of the external eye: a…
Conducting such analyses poses challenges, particularly concerning the risk of encountering spurious results (the multiple comparisons problem). In essence, the higher the number of statistical inferences conducted simultaneously, the greater the likelihood of erroneous conclusions.
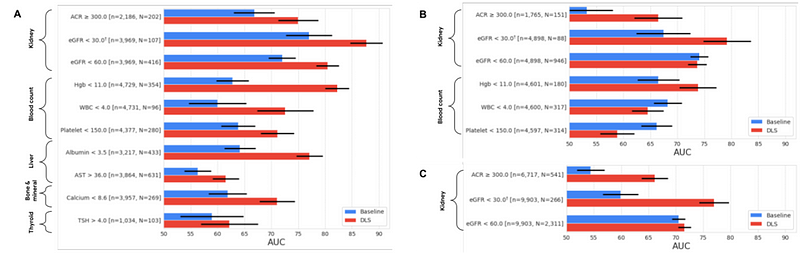
To mitigate these issues, the authors divided their dataset into two segments. They trained the model and conducted analyses on the "development dataset," identifying the nine most promising prediction tasks, and subsequently evaluated the model on the test dataset (while still correcting for multiple comparisons).
The researchers gathered a dataset containing eye images alongside corresponding laboratory test results. They then trained a convolutional neural network designed to predict clinical and laboratory measurements from external eye images. This approach involved multitask classification, with a prediction head for each task to facilitate cross-entropy loss.
For this study, the authors employed Big Transfer (BiT), a model introduced in 2020 that demonstrated strong generalization across various datasets. BiT is structurally similar to ResNet, but incorporates techniques like Group Normalization (GN) and Weight Standardization (WS) during training. The model is available in a GitHub repository.
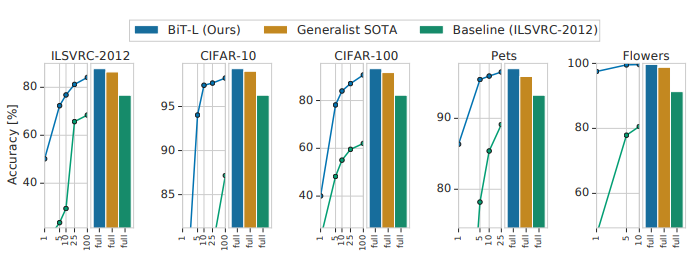
The results surpassed baseline models (e.g., logistic regression based on patient data). While these findings are not yet sufficient for diagnostic applications, they align with initial screening tools (pre-screening for diabetes).
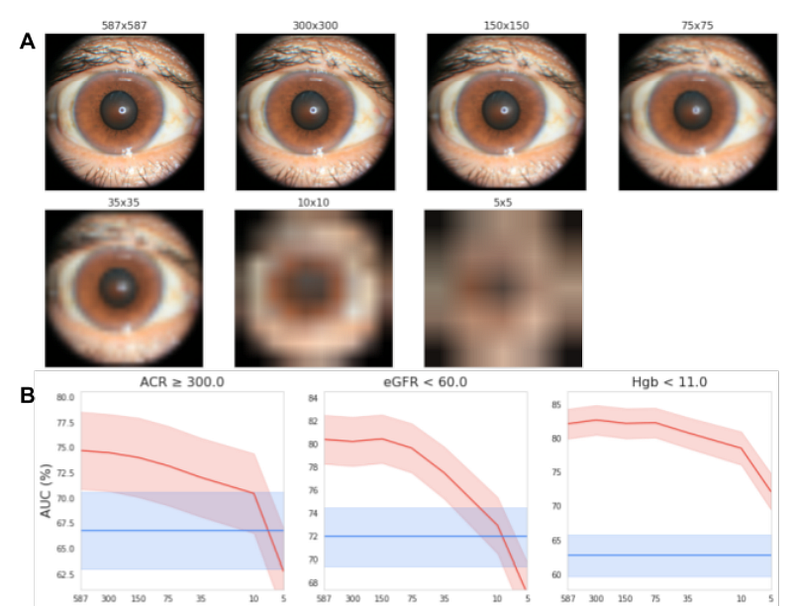
In both studies, images were captured using tabletop cameras (with headrest support) to ensure high-quality images under optimal lighting conditions. The authors also examined whether the model could function with reduced image resolution.
They discovered that the model maintained robust performance even with images downscaled to 150x150 pixels, significantly lower than typical smartphone camera resolutions.
> This pixel count is less than 0.1 megapixels, illustrating the model's adaptability. (source)
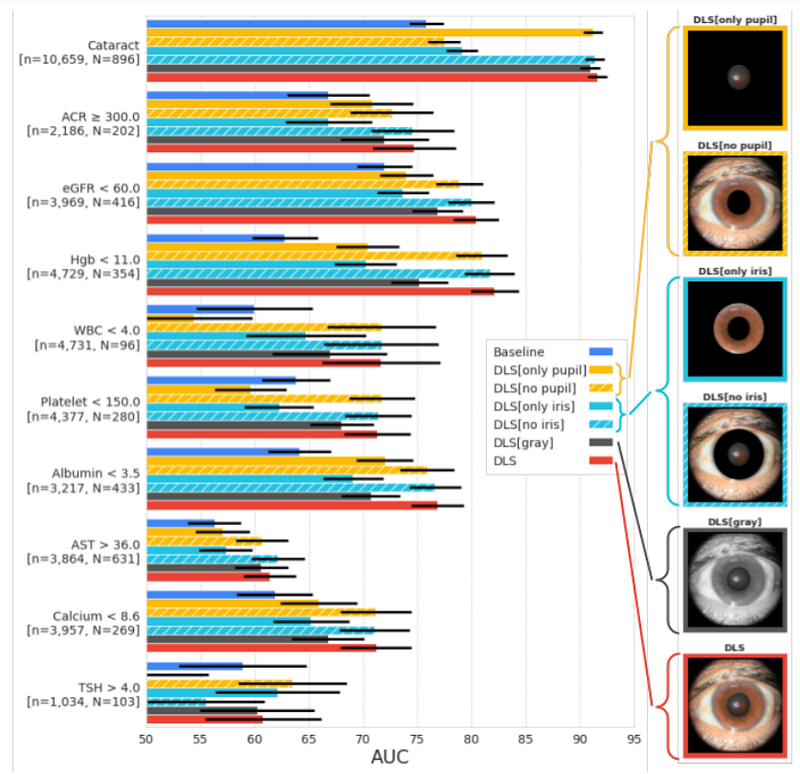
The authors also investigated which image areas were crucial for making predictions. To achieve this, they masked specific regions during training and evaluation (e.g., pupil or iris, transforming images to black and white).
> Results indicated that critical information is not confined solely to the pupil or iris, and that color data remains somewhat important for most prediction targets. (source)
Despite the impressive nature of this research, it remains in the early stages for real-world application. First, the photos were taken under ideal conditions, and further verification is needed with images captured in diverse environments.
> Additionally, the datasets utilized in this work predominantly featured diabetic patients, lacking sufficient representation from critical subgroups—more targeted data collection for refining DLS and evaluating broader populations is necessary before considering clinical use. (source)
Final Reflections
This article illustrates the potential of deep learning models to identify patterns and information in the eye that can be challenging to diagnose. Furthermore, traditional diagnosis often requires expensive tools and invasive tests conducted by trained professionals. Google has demonstrated that similar insights can be derived from eye images.
In the future, a wide array of diseases could potentially be diagnosed (or at least pre-screened) using simple photographs of the outer eye, captured with standard cell phone cameras. Given that quantitative results (like hemoglobin concentration) can be obtained, these methods could facilitate non-invasive patient monitoring.
Technically, it is fascinating to note how the Inception V3 model achieved significant results on its first attempt, showcasing the capabilities of transfer learning and convolutional networks. The authors adapted the models for classification, regression, and multitask classification.
However, many avenues remain open for exploration. Google likely plans to expand its dataset, as mentioned in the article. Moreover, while CNNs were employed, other architectures like Vision Transformers could also be tested. Future experiments may even incorporate language models utilizing patient or doctor notes as input (after all, multi-modal approaches are the future).
At the same time, the potential for these applications to be utilized in areas lacking equipped hospitals raises ethical questions. As observed, the model can predict sensitive information such as age, gender, and lifestyle choices. This technology could be misapplied in problematic contexts.
Regardless, these studies pave the way for exciting new applications. Google is not alone in this endeavor; other groups have also indicated that various diseases, such as hepatobiliary disorders, may be detectable through eye analysis, with more to come in the near future.
If you found this article insightful:
Feel free to explore my other writings, subscribe for updates on new articles, or connect with me on LinkedIn.
You can also visit my GitHub repository, where I plan to gather resources related to machine learning, artificial intelligence, and more.
title: GitHub - SalvatoreRa/tutorial: Tutorials on machine learning, artificial intelligence, data science…
You might also be interested in my recent articles:
title: Making Language Models Similar to the Human Brain title: Google Med-PaLM: The AI Clinician title: Multimodal Chain of Thoughts: Solving Problems in a Multimodal World title: Stable diffusion to fill gaps in medical image data